In the world of natural language processing (NLP), large language models (LLM) have become a hot topic. But what exactly is a large language model, and why is it so important?
In this article, we will explore the concept of large language models, their evolution, applications, limitations, and potential breakthroughs, providing you with a comprehensive understanding of this technology.
1. Understanding Large Language Models
1.1 Definition of a Large Language Model
A large language model is a machine learning algorithm that uses deep neural networks to analyze and understand human language. Essentially, it is a program that is trained on vast amounts of text data and can then generate or analyze language with a high degree of accuracy.
Related article: What Is Computer Vision And How Does It Work?
Large language models have revolutionized the field of natural language processing (NLP) and have become increasingly popular in recent years. They are used in a wide range of applications, including language translation, text summarization, and even chatbots.
One of the most well-known examples of a large language model is OpenAI’s ChatGPT, which has been praised for its ability to generate human-like text and complete a wide range of language tasks.
Large language models have the ability to generate human-like text, including news articles, product descriptions, and even fictional stories. They can also be used to analyze existing text, providing insights into sentiment analysis, topic modeling, and more.
1.2 Key Components of Large Language Models
Large language models rely on several key components to function, including neural networks, language models, and attention mechanisms. Neural networks are artificial networks that mimic the behavior of neurons in the brain. They are used to process and analyze language data in large language models. These networks are typically composed of multiple layers, with each layer processing different aspects of the input data.
Language models are statistical models that estimate the probability of a given word or sequence of words appearing in a sentence. They are used to predict the likelihood of the next word in a sequence. In large language models, these models are typically based on recurrent neural networks (RNNs) or transformer models.
Attention mechanisms are used in large language models to identify which parts of the text are most relevant to generating or analyzing language. They allow the model to focus on specific words or phrases and understand the context in which they appear. Attention mechanisms have become increasingly important in recent years and have been incorporated into many state-of-the-art language models.
Large language models are trained on vast amounts of text data, typically using unsupervised learning methods. This means that the model is not explicitly told what to learn, but rather learns from the patterns and structures present in the data.
During training, the model is presented with a sequence of words and is asked to predict the next word in the sequence. The model’s predictions are compared to the actual next word in the sequence, and the weights and parameters of the model are adjusted to minimize the difference between the predicted and actual words.
Once a large language model has been trained, it can be fine-tuned on specific tasks, such as text generation or sentiment analysis. Fine-tuning involves adjusting the weights and parameters of the model to better suit the specific task at hand.
Overall, large language models have revolutionized the field of natural language processing and have the potential to transform many industries. As research in this area continues, we can expect to see even more impressive language models in the future.
2. Evolution of Language Models
The development of language models has come a long way since the 1950s. From the creation of the Markov model to the rise of deep learning techniques and the emergence of transformer models, language models have undergone significant changes to improve their accuracy and efficiency.
2.1 Early Language Models
The Markov model, created in the 1950s, was one of the earliest language models. This model was based on probabilities and used to predict the probability of a given word appearing in a sequence. The model assumed that the probability of a word appearing in a sequence was only dependent on the previous word. However, this model had its limitations as it could not take into account the context of the word in a sentence.
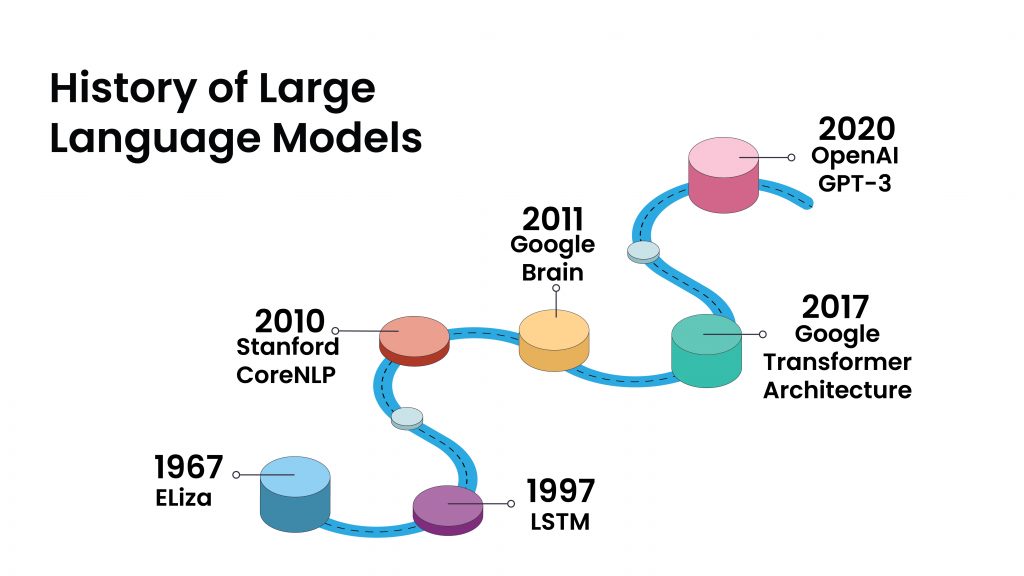
In the 1960s, hidden Markov models were introduced, which used a more sophisticated approach to predicting language. These models were able to take into account the context of the word in a sentence by using a probability distribution over a sequence of words. Hidden Markov models were widely used in speech recognition and natural language processing applications.
2.2 The Rise of Deep Learning in NLP
Deep learning has revolutionized natural language processing in recent years. Deep learning is a type of machine learning that uses neural networks to analyze data. In NLP, deep learning techniques have been used to improve language models and achieve impressive results.
Deep learning models are able to learn from large amounts of data and can automatically extract features from text. This has led to significant improvements in language modeling tasks such as machine translation, sentiment analysis, and text classification. Deep learning models can also handle complex sentence structures and capture the nuances of language, making them more accurate than traditional models.
2.3 The Emergence of Transformer Models
Transformers are a type of neural network architecture that was introduced in 2017 with the creation of the Transformer model. This model revolutionized NLP by allowing the model to understand the context of a word based on the words that come before and after it.
Read more: What is Artificial General Intelligence (AGI)? You Should Read This!
The Transformer model uses a self-attention mechanism that enables it to attend to different parts of the input sequence. This mechanism allows the model to capture long-range dependencies and understand the context of a word in a sentence. The Transformer model has achieved impressive results on a range of NLP tasks and has become the basis for many of the most popular large language models today.
In conclusion, the evolution of language models has been driven by the need to improve their accuracy and efficiency. From the Markov model to the Transformer model, language models have undergone significant changes to better understand the complexities of language. With the continued advancements in deep learning and NLP, we can expect even more sophisticated language models in the future.
3. Popular Large Language Models
Language models have come a long way in the past few years, with many large models being developed that can perform a wide range of natural language processing (NLP) tasks. In this article, we will discuss some of the most popular large language models that are being used today.
3.1 GPT-3 & GPT-4: OpenAI’s Generative Pre-trained Transformer
GPT-3 is one of the largest and most powerful language models available today, with over 175 billion parameters. It has been trained on a massive amount of text data and has demonstrated impressive abilities in many language-related tasks, including text generation, language translation, and even coding. One of the most impressive things about GPT-3 is its ability to generate human-like text.

Reportedly, the newer version GPT-4 is trained on much more parameters (up to 100 trillion). It can write articles, stories, and even poetry that can be difficult to distinguish from text written by a human. This has led to some concerns about the potential misuse of such a powerful tool, but it also has many potential applications in fields such as content creation, chatbots, and even creative writing.
3.2 BERT: Bidirectional Encoder Representations from Transformers
BERT is a language model developed by Google that has been fine-tuned on a wide variety of NLP tasks. It is known for its ability to understand the context of a word based on both the words that come before and after it. This makes it particularly useful for tasks such as sentiment analysis, where understanding the context of a word is crucial for determining its meaning.
BERT has also been used in a variety of other applications, such as question-answering and text classification. Its ability to handle multiple tasks with high accuracy has made it a popular choice for many NLP researchers and practitioners.
3.3 T5: Text-to-Text Transfer Transformer
T5 is a language model developed by Google that is designed to handle a wide range of language tasks, including text generation, summarization, and even question-answering. It has already shown impressive results when it comes to machine translation and other language-related tasks.
One of the unique features of T5 is its ability to perform “text-to-text” transfer. This means that it can take a piece of text in one language and translate it into another, summarize a long article into a short summary, or even generate code based on a natural language description of a task.
Overall, these large language models represent a significant advancement in the field of natural language processing and have the potential to revolutionize many industries. As researchers continue to develop even more powerful models and find new applications for them, we can expect to see even more exciting developments in this field in the years to come.
4. Applications of Large Language Models
Large language models have become increasingly popular in recent years due to their ability to understand and generate human-like language. These models are trained on vast amounts of text data and are capable of performing a wide range of tasks. Let’s take a closer look at some of the most common applications of large language models.
4.1 Natural Language Understanding
One of the primary applications of large language models is natural language understanding. These models can be used to analyze text data and gain insights into sentiment analysis, topic modeling, and more. Natural language understanding is a crucial component in many industries, including marketing, customer service, and healthcare.
Also read: TOP 10 AI Startups in 2023 You Need to Watch (part 2)
For example, in marketing, large language models can be used to analyze social media posts and customer reviews to gain insights into customer sentiment. This information can then be used to improve marketing campaigns and product development strategies.
4.2 Text Generation and Summarization
Large language models are also used for text generation and summarization. They can be trained to generate human-like text, including news articles, product descriptions, and even fictional stories. Text generation models can be used to automate content creation, saving time and resources for businesses and content creators.
On the other hand, text summarization models can be used to summarize long documents into shorter, more digestible summaries. This is particularly useful in industries such as journalism and research, where large amounts of information need to be processed quickly.
4.3 Machine Translation
Machine translation is another area where large language models have shown promise. These models can be trained to translate text between languages with a high degree of accuracy, making it possible to communicate across language barriers. This is particularly useful in industries such as e-commerce, where businesses need to communicate with customers from all over the world.
However, machine translation is not without its challenges. Language is complex, and there are many nuances that can be lost in translation. Large language models are constantly being improved to address these challenges, but there is still much work to be done.
4.4 Sentiment Analysis
Sentiment analysis is the process of analyzing text data to determine the emotional tone of the content. Large language models can be used to perform sentiment analysis on social media posts, customer reviews, and other types of text data. This information can then be used to improve customer service, product development, and marketing strategies.
For example, a business may use sentiment analysis to monitor social media for customer complaints. They can then use this information to address these complaints and improve customer satisfaction.
4.5 Chatbots and Conversational AI
Large language models are also used to power chatbots and other types of conversational AI. These models can be trained to understand natural language input from users and generate human-like responses. Chatbots are becoming increasingly popular in industries such as customer service, where they can provide 24/7 support to customers.
Conversational AI is also being used in healthcare to provide personalized support to patients. For example, a chatbot may be used to help patients manage chronic conditions by providing information and reminders about medication and lifestyle changes.
Large language models basically have a wide range of applications, from natural language understanding to chatbots and conversational AI. As these models continue to improve, we can expect to see them being used in even more industries and applications in the future.
5. Limitations and Challenges
As the field of natural language processing continues to evolve, there are several limitations and challenges that researchers and developers must contend with. Some of the most pressing challenges include:
5.1 Computational Resources and Energy Consumption
One of the biggest challenges when it comes to large language models is the computational resources required to train and run these models. Training a large language model requires massive amounts of data and processing power, which can be costly and environmentally damaging.
For example, the GPT-3 language model, which has 175 billion parameters, required an estimated 3.2 billion kWh of energy to train. This is equivalent to the energy consumption of approximately 300,000 homes in the United States for an entire year. As such, researchers are exploring ways to reduce the energy consumption of large language models, such as through more efficient hardware or algorithms.
5.2 Bias and Ethical Concerns
Another challenge associated with large language models is the risk of bias and ethical concerns. These models are trained on vast amounts of data, and if that data is biased in some way, it can result in biased language generation or analysis.
For example, a language model trained on text from predominantly white, male authors may not be as accurate or effective when generating text about topics related to women or people of color. Additionally, language models can perpetuate harmful stereotypes or language if they are not carefully monitored and evaluated.
As such, researchers and developers are working to identify and mitigate sources of bias in language models, such as through more diverse training data or algorithms that explicitly account for bias.
5.3 Model Interpretability and Explainability
Large language models can be difficult to interpret and explain, which can make it challenging to understand how these models are making decisions. This is a significant concern when it comes to ethical considerations around the use of these models.
For example, if a language model is used to make decisions about hiring or lending, it is important to understand how the model arrived at its decision in order to ensure that it is not making biased or discriminatory choices. However, the complex architecture and sheer size of many language models can make it difficult to trace the decision-making process.
Researchers are exploring ways to make language models more interpretable and explainable, such as through visualization tools or techniques that highlight which parts of the input data were most influential in the model’s decision-making process.
6. The Future of Large Language Models
6.1 Potential Breakthroughs and Innovations
Despite the challenges associated with large language models, there is enormous potential for breakthroughs and innovations in this field. As these models continue to improve, they will be able to handle more complex language-related tasks and generate even more human-like text.
One potential breakthrough is the ability of large language models to understand and generate natural language in multiple languages. This could revolutionize the way we communicate with people from around the world, breaking down language barriers and enabling more effective communication across cultures.
Another potential breakthrough is the ability of large language models to understand and generate not just text, but also speech. This could lead to the development of more advanced virtual assistants and chatbots, capable of understanding and responding to spoken language with greater accuracy and nuance.
6.2 Expanding the Scope of Applications
As large language models become more powerful and versatile, we can expect to see them applied in a wide range of fields beyond NLP. These models have the potential to revolutionize how we interact with technology, enabling us to communicate more effectively with machines.
One area where large language models could have a significant impact is in healthcare. These models could be used to analyze medical records and help doctors make more accurate diagnoses and treatment recommendations. They could also be used to develop more effective patient communication tools, such as chatbots that can answer common health-related questions.
Large language models could also be used in education, helping to personalize learning experiences for students and providing more effective feedback on written assignments. In addition, these models could be used to analyze and summarize large amounts of research data, making it easier for scientists to stay up-to-date with the latest developments in their fields.
6.3 Addressing Limitations and Ethical Considerations
Finally, it will be critical to address the limitations and ethical considerations associated with large language models. This includes finding ways to reduce the environmental impact of these models, ensuring that they are free from bias, and making them more transparent and explainable.
One way to reduce the environmental impact of large language models is to develop more efficient hardware and software solutions. This could involve using more energy-efficient processors or developing algorithms that require less computational power to run.
To ensure that large language models are free from bias, it will be important to train them on diverse datasets that accurately reflect the full range of human experiences and perspectives. In addition, it will be important to develop tools to detect and correct bias in these models as they are being developed and deployed.
Making large language models more transparent and explainable will also be critical. This will involve developing tools to help users understand how these models are making decisions and generating text, as well as providing clear explanations for any errors or inaccuracies that may arise.
Conclusion
Large language models are a fascinating and powerful technology with enormous potential for innovation and breakthroughs. Despite the challenges associated with these models, we can expect to see them applied in a wide range of fields in the coming years, from NLP to other areas of AI.
It will be crucial to address the limitations and ethical concerns associated with these models, but if we can do so successfully, we are likely to see the emergence of even more advanced language technology in the future.









